728x90
[근육빵빵] - Sprint 2 회고록
기간: 2025.02.03 - 2025.2.14
1. 이번 목표
- 랜덤포레스트 모델 성능 최적화
- 그리드서치를 통한 최적 파라미터 도출
- 모델 성능 평가 및 시각화 분석
2. 진행 상황
1. 완료된 작업
- 랜덤포레스트 모델 구현 및 최적화 - [40시간]
- GridSearchCV를 활용한 하이퍼파라미터 최적화
- 다양한 성능 지표 분석 및 시각화
- 최종 모델 평가 및 결과 도출
- 팀 내 모델 비교 분석
- 최적의 모델 평가 및 결과 도출
2. 다음 예정 작업
- 시연 페이지 구축
- readme 작성
3. KPI 현황
- 목표 대비 진척률: 70%
- 품질 지표: 70%
- 팀 생산성: 100%
4. 주요 배운 점
- 기술적 측면:
- 실제 클래스와 예측률이 일치하는 지 파악하는 시각화를 만들어 봄. (Calibration Curve)
- 협업 측면:
- 협업하여 다양한 모델 성능을 비교 분석할 수 있었음
- 프로세스 측면:
- 복잡한 모델이 아니어도 충분한 성능 달성 가능
- 시각화를 통한 모델 평가의 중요성
6. 다음 계획
- [구체적인 목표/계획]
- [개선할 점]
- [필요한 지원사항]
내가 맡은 모델은 랜덤포레스트였다. gridsearchCV를 이용해 최적의 파라미터를 찾고,
# 그리드서치를 위한 하이퍼파라미터
param_grid = {
'n_estimators': [100, 200, 300],
'max_depth': [10, 20, 30, None],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4],
'max_features': ['auto', 'sqrt'],
'class_weight': [None, 'balanced']
}
rf = RandomForestClassifier(random_state=42)
# 그리드서치를 사용한 하이퍼파라미터 분석
grid_search = GridSearchCV(
estimator=rf,
param_grid=param_grid,
scoring='f1',
cv=5,
verbose=1,
n_jobs=-1
)
grid_search.fit(X_train, y_train)
# 최적 파라미터 출력
print("\n=== 최적 하이퍼파라미터 ===")
print(grid_search.best_params_)
# === 최적 하이퍼파라미터 ===
# {'class_weight': 'balanced', 'max_depth': 30, 'max_features': 'sqrt', 'min_samples_leaf': 2, 'min_samples_split': 5, 'n_estimators': 200}
모델 성능 평가와 특성 중요도에 관해 지표를 냈다.
=== 최적화된 모델 성능 평가 ===
정확도 (Accuracy): 0.9163
정밀도 (Precision): 0.8358
F1 점수: 0.8337
=== 특성 중요도 (상위 5개) ===
feature importance
10 Lifetime 0.307297
12 Avg_class_frequency_current_month 0.165515
7 Age 0.120870
11 Avg_class_frequency_total 0.108081
9 Month_to_end_contract 0.095203
어떤 성능을 갖고 있고, 잘 재현되고 있는지 확인하고자 시각화로 도출했다.
정밀도와 재현율의 관계

결론:
- 모델의 정밀도(Precision)는 재현율(Recall)이 낮을 때(1에 가까운 Recall 값) 거의 1에 가까운 값을 유지. -> 모델이 이탈 고객을 잘 예측하고 있음을 나타냄
- 재현율이 증가함에 따라 정밀도는 다소 감소하는 경향이 있지만, 여전히 높은 정밀도를 유지하고 있다. -> 이탈 고객을 잘 찾아내면서도 많은 잘못된 이탈 예측을 하지 않음을 보여줌
혼동 행렬 시각화

결론:
- 진짜 음성 (TN): 565건 - 모델이 이탈하지 않을 것으로 예측했고 실제로도 이탈하지 않음. -> 모델이 대부분의 음성 샘플을 잘 분류했음
- 거짓 양성 (FP): 33건 - 이탈할 것으로 예측했으나 실제로는 이탈하지 않음. -> 모델의 오탐지 비율이 상대적으로 낮음
- 거짓 음성 (FN): 34건 - 이탈하지 않을 것으로 예측했으나 실제로 이탈함. -> 이탈 고객을 놓치는 경우가 다소 있음
- 진짜 양성 (TP): 168건 - 이탈할 것으로 예측했고 실제로 이탈함. -> 모델이 이탈 고객을 잘 찾아냈음을 나타냄.
- 전반적으로 모델의 성능이 우수하며, 이탈하지 않을 고객과 이탈할 고객을 잘 구분하고 있음을 보여준다.
교차 검증 시각화
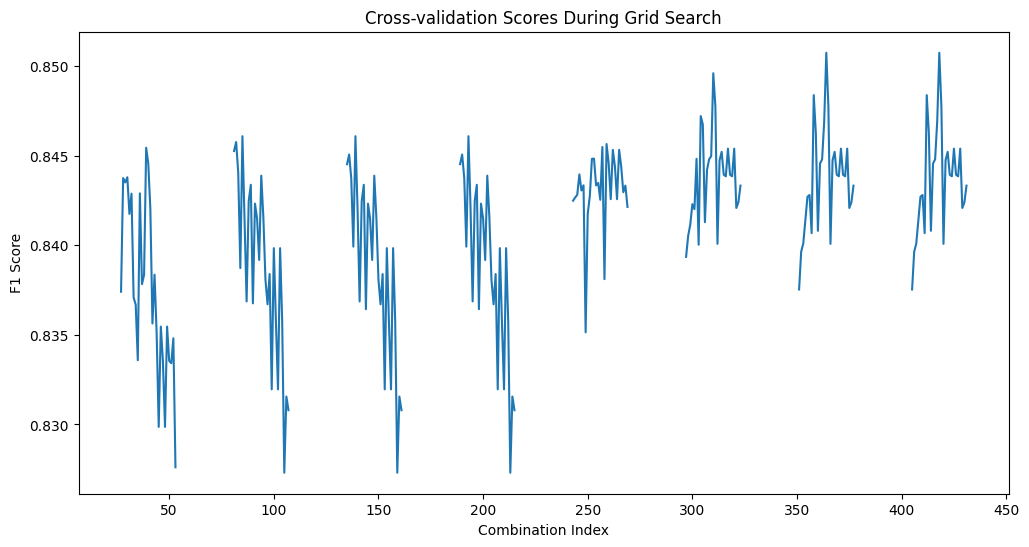
결론:
- F1 점수가 다양한 하이퍼파라미터 조합에서 변화하는 모습을 보여준다.
- 점수의 변동성이 있지만, 전반적으로 0.83에서 0.85 사이의 값을 유지하고 있음.
- 이는 모델이 다양한 하이퍼파라미터 조합에 대해 안정적인 성능을 보인다는 것을 나타낸다. 특히, 특정 조합에서 성능이 뛰어난 점수를 기록하고 있음을 알 수 있음.
중요 하이퍼파라미터 영향 분석

결론:
- 모델의 성능은 n_estimators와 max_depth에 따라 달라지지만, 성능 차이가 크지 않음.
- max_depth가 10일 때의 성능이 가장 높게 나타나며, 다른 깊이에서도 비슷한 성능을 유지하고 있음.
- 이 결과는 모델이 복잡한 구조를 가지지 않고도 높은 성능을 낼 수 있다는 것을 보여준다.
Calibration Curve - 모델의 예측 확률이 실제 클래스 확률과 얼마나 잘 일치하나

결론:
- 모델의 예측이 잘 보정(calibrated)되었음을 나타내며, 예측 확률이 높을수록 실제 양성 비율도 증가
- 그래프가 대각선(Perfectly Calibrated)에 가까울수록 모델의 예측이 신뢰할 수 있음을 의미
- 이 경우, 모델의 예측이 비교적 잘 보정되어 있지만, 예측 확률이 0.5 이하일 때와 0.9 이상일 때 실제 양성 비율이 다소 떨어지는 경향이 있다. 이는 특정 구간에서 모델의 신뢰도를 향상시킬 여지가 있음을 시사.
ROC 커브

결론
- 모델 성능: AUC 값이 0.96인 경우, 모델의 분류 성능이 매우 우수. 이는 모델이 실제 양성 사례를 잘 식별하고, 잘못된 양성 예측을 최소화하고 있음을 보여줌.
- 신뢰성: 이 정도의 AUC 값은 일반적으로 신뢰할 수 있는 예측을 제공하며, 비즈니스 또는 연구 목적에 맞게 모델을 활용할 수 있는 좋은 기준이 된다.
- 의사결정 지원: 이러한 성능 지표는 향후 고객 이탈 예측 또는 기타 분류 문제 상황에서 모델의 신뢰성을 높이고, 의사결정 과정을 지원하는 데 중요한 역할을 할 수 있음.
결론
- 모델 성능 분석:
- 혼동 행렬(Confusion Matrix)을 보면:
- 진짜 음성(TN): 565건 (이탈하지 않을 것으로 예측했고 실제로 이탈하지 않음)
- 거짓 양성(FP): 33건 (이탈할 것으로 예측했으나 실제로 이탈하지 않음)
- 거짓 음성(FN): 34건 (이탈하지 않을 것으로 예측했으나 실제로 이탈함)
- 진짜 양성(TP): 168건 (이탈할 것으로 예측했고 실제로 이탈함)
- 모델 성능 지표:
- 정확도 91.63%: 전체 예측 중 약 92%가 정확함
- 정밀도 83.58%: 이탈 예측 중 실제 이탈한 비율
- F1 점수 83.37%: 정밀도와 재현율의 조화평균으로 양호한 수준
- 하이퍼파라미터 최적화 결과:
- n_estimators(트리 개수)와 max_depth(트리 깊이)에 따른 성능 변화를 보여줌
- 200~300개의 트리와 다양한 깊이에서 비슷한 성능을 보임
- 성능 차이가 크지 않아 간단한 모델(낮은 깊이)로도 충분한 성능 달성 가능
- 특성 중요도 분석:
- Lifetime(고객 생애 기간): 30.7%로 가장 중요
- 현재 월 평균 수업 빈도: 16.6%로 두 번째로 중요
- 나이: 12.1%
- 전체 평균 수업 빈도: 10.8%
- 계약 종료까지 남은 기간: 9.5%
- ROC 곡선 및 AUC 분석:
- ROC 곡선은 모델이 양성과 음성을 잘 구분하고 있음. (곡선이 왼쪽 위 코너에 가까워질수록 모델의 성능이 우수함)
- AUC 값이 0.96으로 매우 높아, 모델이 96%의 확률로 양성과 음성을 구분할 수 있음을 보여줌. -> 모델의 분류 성능이 뛰어나며 신뢰할 수 있는 예측을 제공한다는 것을 의미.
최종 결론:
- 모델의 예측 성능이 전반적으로 우수하며, 특히 91.63%의 높은 정확도를 보임
- 고객 이탈 예측에 있어 고객의 생애 기간과 수업 참여도가 가장 중요한 지표
- 하이퍼파라미터 튜닝 결과, 복잡한 모델이 아니어도 충분한 성능을 낼 수 있음
- ROC 곡선과 AUC 분석 결과, 모델의 분류 성능이 매우 뛰어나며, 신뢰할 수 있는 예측을 제공함
- 실제 활용을 위해서는 특히 고객의 생애 기간과 수업 참여도를 중점적으로 모니터링하고, 이탈 위험이 있는 고객들에 대한 선제적 관리가 필요
우리 팀에서 아래와 같은 결과로 XGBoost가 가장 좋은 성능을 보여주고 있었다.

728x90
'SKN_09_Project' 카테고리의 다른 글
| [SK캠프 9기] 미니_MZ밈_250228 (밈 자동 생성기) (0) | 2025.03.02 |
|---|---|
| [SK캠프 9기] 3번째_근육빵빵_250211~250214 (시연 및 발표) (2) | 2025.02.17 |
| [SK캠프 9기] 3번째_근육빵빵_250203~250206 (프로젝트 설정 및 EDA 수립) (1) | 2025.02.06 |
| [SK캠프 9기] 2번째_무빙_250127~0203 (영화흥행 예측 시스템, 진짜 끝) (0) | 2025.02.04 |
| [SK캠프 9기] 2번째_무빙_250122~250124 (머신러닝까지) (0) | 2025.01.27 |