728x90
여러 모델의 협력 학습
오늘은 앙상블 학습 및 랜덤 포레스트에 대해 알아보자.
| 오늘의 배움 |
|
1. 앙상블 학습 및 랜덤 포레스트
앙상블 학습이란?
여러 개의 모델(약한 학습기)을 결합하여 하나의 강력한 모델을 만드는 방법
-> 여러 명의 전문가가 모여 의견을 모으는 것처럼, 다양한 모델의 예측을 결합하여 더 나은 결과를 도출하는 방법
📚 실제 예시로 이해하기
- 의사 진단: 여러 의사의 의견을 종합하여 최종 진단을 내리는 것
- 투자 결정: 다양한 전문가의 의견을 종합하여 투자 결정을 하는 것
- 주식 가격 예측: 여러 예측 모델의 결과를 종합하여 최종 예측
- 질병 진단: 다양한 검사 결과를 종합하여 진단
2. 핵심 개념 정리
- 투표 기반 분류기 (Voting Classifier)
- 정의: 여러 분류기의 예측 결과를 투표로 결정 -> voting 기법
- 특징:
- 다수결 투표(Hard Voting): 각 분류기의 예측 중 다수결로 최종 클래스 선택
- 확률 평균 투표(Soft Voting): 각 분류기가 예측한 확률값의 평균을 계산하여 가장 높은 확률의 클래스 선택
- 예시: 로지스틱 회귀, 결정 트리, SVM 결합
- 배깅(Bootstrap Aggregating)과 페이스팅(Pasting)
- 정의: 데이터 샘플링 방식으로 여러 모델 학습
- 특징:
- 베깅(Bagging): 데이터 샘플을 복원 추출하여 학습 데이터로 사용한다.
- 페이스팅(Pasting): 데이터 샘플을 비복원 추출하여 학습 데이터로 사용한다.
- 예시: 랜덤 포레스트의 기반이 되는 기술
- 부스팅
- 정의: 순차적으로 모델을 개선하며 학습
- 특징: 이전 모델의 오류를 보완
- 예시:
- AdaBoost: 이전 모델이 잘못 분류한 샘플에 더 많은 가중치를 부여
- Gradient Boosting: 모델의 예측 오차(잔차)에 기반하여 다음 모델을 학습
- XGBoost, LightGBM, CatBoost 등
- 랜덤 포레스트 (Random Forest)
- 정의: 여러 개의 결정트리로 평균(또는 다수결)으로 결과 도출하는 방법
- 특징:
- 랜덤 패치(Random Patches) : 샘플과 특성 모두를 랜덤하게 선택하여 학습
- 랜덤 서브스페이스(Random Subspaces) : 전체 데이터를 사용하지만, 특성의 일부만 무작위로 선택하여 학습
- 장점: 과대 적합 방지, 모델 다양성 증가에 유리
- 스태킹 (Stacking)
- 정의: 여러 모델의 예측값으로 새로운 모델 학습
- 특징: 각 모델의 강점을 결합하여 성능 극대화함
# 랜덤 포레스트
from sklearn.ensemble import RandomForestClassifier
rf_clf = RandomForestClassifier(n_estimators=100)
rf_clf.fit(X_train, y_train)
# Gradient Boosting
from sklearn.ensemble import GradientBoostingClassifier
gb_clf = GradientBoostingClassifier(n_estimators=100)
gb_clf.fit(X_train, y_train)# 스태킹
from sklearn.ensemble import StackingClassifier
stacking_clf = StackingClassifier(
estimators=[('rf', RandomForestClassifier()),
('gb', GradientBoostingClassifier())],
final_estimator=LogisticRegression()
)
[참고] Boosting model
더보기
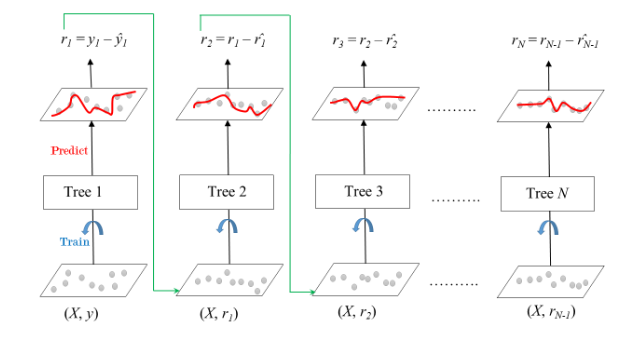
1. GBM (Gradient Boosting Machine)
가중치 부여를 통해 오류를 개선해 나가면서 학습하는 방식이다.
- 첫 번째 모델이 예측을 하고, 거기서 틀린 것을 가지고 그 다음 모델이 그 틀린 것을 개선을 시킨다.
- 그리고 이 모델이 또 학습으로 인해서 나온 결과 중에 잘못된 것을 그 다음 모델이 개선을 시키는 방식으로 만드는 것이 부스팅 방식이다.
2.XGBoost란
트리 기반의 앙상블 학습에서 가장 인기 있는 모델 중 하나.
- 장점: 다른 모델 대비 성능이 매우 좋다.
- 단점: 성능이 좋은 만큼 파라미터가 늘어나면 속도가 늦어진다.
⇒ 다른 모델에 비해 압도적 성능을 보이므로 단점을 감안하고 사용한다. (결과를 좌우하는 중요한 지표들을 XGBoost가 찾아준다.)
https://xgboost.readthedocs.io/en/stable/index.html
[ 주요 부스터 파라미터 ]
- learning-rate : 0에서 1 사이의 값을 지정하며 부스팅 스텝을 반복적으로 수행할 때 업데이트 되는 학습률 값이다. 기본값은 0.1이고 보통은 0.01~0.2 사이의 값을 선호한다.
- max-depth : 트리 기반 알고리즘의 max_depth와 같은 것으로, 해당 값이 높으면 과적합 가능성이 높아지므로 보통 3~10 사이의 값을 적용한다.
- n-estimators : 학습을 몇 번 시킬지 결정한다.
- sub sample : 트리가 커져서 과적합되는 것을 제어하기 위해 데이터의 샘플링 비율을 지정한다. 0~1 사이의 값을 지정 가능하고 기본값은 0.5이다. 한 번 트리를 돌릴때마다의 샘플 비율을 의미한다.
- 최적의 파라미터를 자동으로 찾아주는 Optuna와 같은 라이브러리를 활용할 수 있다.
[ 학습 태스크 파라미터 ]
- objective : 최솟값을 가져야 할 손실 함수를 정의한다. 주로 사용되는 손실함수는 이진 분류인지 다중 분류인지에 따라 달라진다.
- (이진분류 ‘binary:logistic’, 다중분류 ‘multi:softmax’)
- eval_metrix : 검증에 사용되는 함수를 정의한다. 기본값은 회귀인 경우 rmse, 분류일 경우 error이다. 로스값을 관측할 수 있는 수치적인 기법들이 몇가지 있는데 아래와 같다.
- rmse : Root Mean Square Error
- mae : Mean Absolute Error
- logloss : Negative log-likelihood
- error : Binary classification error rate (0.5 threshold)
- merror : Multiclass classification error rate
- mlogloss : Multiclass logloss
- auc : Area under the curve
3. LightGBM이란
LightGBM은 학습시간이 오래 걸리는 XGBoost의 단점을 보완하기 위해서 나온 모델이다.
- LightGBM는 XGBoost보다 학습에 걸리는 시간이 훨씬 적고, 메모리 사용량도 적다는 장점이 있다.
🤓 학습 느낀점
- 이해하기 어려웠던 부분: 각 앙상블 방법의 세부적인 차이점
- 흥미로웠던 부분: 여러 모델을 결합하여 성능을 높일 수 있다는 점
- 추가 학습 필요: 각 모델의 하이퍼파라미터 튜닝
- 다음 학습 계획: 실제 데이터셋으로 앙상블 모델 구현해보기
728x90
'Develop > ML·DL' 카테고리의 다른 글
| 머신러닝 데이터 처리 및 모델 훈련 과정 정리. (0) | 2025.01.28 |
|---|---|
| 차원 축소를 알아보자. (2) | 2025.01.25 |
| 서포트 벡터 머신(SVM)을 알아보자. (2) | 2025.01.21 |
| 결정 트리를 알아보자. (2) | 2025.01.21 |
| 분류와 로지스틱 회귀를 알아보자. (0) | 2025.01.20 |